内容类产品——个性化推荐和热度算法
1 初期阶段
个性化推荐不是产品首次发布就能自带的。无论是基于用户行为的个性化,还是基于内容相似度的个性化,都建立在大量的用户数和内容的基础上。
产品发布之初,一般两遍的数据都有残缺,因此个性化推荐并不能完整开展。
故,产品发展初期 推荐内容一般采用更加聚合的“热度算法”,把热点的内容有限推荐给用户;虽无法做到基于兴趣和习惯为每一个用户做到准确化推荐,但能覆盖到大部分用户需求,而且启动成本比个性化推荐算法低很多。
2 热度算法
2.1 热度算法基本原理
新闻热度分 = 初始热度分 + 用户交互产生的热度分 – 随时间衰减的热度分
Score = S0 + S(Users) – S(Time)
1、新闻入库后,被系统赋予一个初始热度值,该新闻进入推荐列表进行排序
2、随着新闻不断被用户点击阅读,收藏,分享...... 用户行为被视作帮助提升新闻热度,系统需要为每种新闻重新赋予热度值
3、同时,新闻自身具有较强的实效性,随着时间的变化而变的陈旧,进而热度衰减
2.2 初始热度需要不一致
由于不同的新闻本身属性所在,受欢迎程度是不一样的。
如:娱乐类比文化类受欢迎程度高;
某些突发事件的受关注度也会急剧变高;
体育活动期间,体育类的关注度也会继续变高;
解决方案:把初始热度设置为变量。
(1)按照新闻类别给予新闻不同的初始热度,让用户关注高的类别获得更高的初始热度分,从而获得更多的曝光

(2)对于重大事件的报道,可通过热词匹配来使其入库即具备更高的热度
对大型新闻站点的头条,Twitter热点,竞品头条监控和爬取,并将关键词维护到热词库并保持更新;
每条新闻入库时,用新闻的关键词去匹配热词库,匹配度越高,则有越高的初始化热度;
2.3 用户行为分规则不是固定不变的
有了初始热度分之后,需要考虑热度分的变化。
1、先明确用户哪些行为会影响到热度分值,并对这些行为赋予一定的得分规则
2、例如:点击(click)、收藏(favor)、分享(share)、评论(comment),对行为赋予分数,即可得到实时用户行为分:
S(Users) = 1click + 5favor + 10comment + 20share
示例分数:但分数值不是一成不变的,做内容运营时需要对行为分不断调整
click , 1分,
favor,5分,
share,10分,
comment ,20分,
当用户规模小的时候,各项事件量小,需要提高每个事件的行为分来提升用户行为的影响力;
当用户规模变大时,行为分也应该相应的慢慢降低;
2.4 热度随时间的衰减不是线性的
1、由于内容的时效性,已发布的新闻热度值必须随时间流逝二衰减,并且衰减趋势越来越快,直至趋于0热度。
如果一条新闻(内容)需要长期处于靠前的位置,随时间推移必须有越来越多的用户来维持。
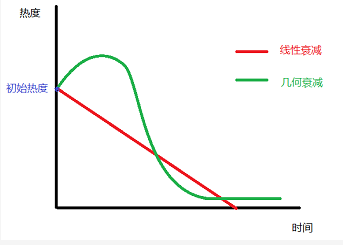
2、要求推荐给用户的新闻(内容)必须是24h以内,故 衰减算法必须保证在24h后 内容热度一定会衰减到很低。
线性衰减:当新闻突然有大量用户点击阅读,获得极高热度分,就会持续排名靠前,会使用户感觉内容更新较慢
指数衰减:参考牛顿冷却定律,时间衰减因子应该是一个类似于指数函数:
T(Time) = e ^ (k*(T1 – T0))
其中T0是新闻发布时间,T1是当前时间
而热度的发展最终是一个无限趋近于0热度的结果,最终算法调整为:
Score = ( S0(Type) + S(Users) ) / T(Time)
2.5 其它影响因素
“赞” “踩” “不推荐此类”等选项的存在
建议:把所有的调整指标均做成可配项,如:初始热度分,行为事件分,衰减因子等
3 个性化推荐
个性化推荐 一般常用的两种解决方案:一是基于内容的相关推荐,二是基于用户的协同过滤(对用户规模有较高要求)
3.1 基于内容的推荐算法
“新闻(内容)特征向量”来标示新闻的属性,以及用来对比内容之间的相似度;
新闻(内容)特征向量是由内容所包含的关键词所决定的;
把新闻(内容)看作所有关键词(标签)的合集;
两个新闻(内容)的关键词越类似,则两个内容是相关的可能性更高;
3.1.1 分词
得到新闻(内容)特征向量的第一步, 就是要对新闻(内容)进行关键词级别的拆分。
- 分词
- 正常词库:把内容拆解为词语的标准
停用词 主要是没有实际含义的,如“the” "that" "are"之类的助词,如"behind" "under" 之类的介词, 以及很多常用的高频但没有偏向性的动词"think" "give";
- 停用词库:分词过程中需要首先去掉的内容
分词之前剔除停用词,对剩下的标准词库进行拆词,拆词方法包含正向匹配拆分,逆向匹配拆分,最少切分等常用算法
由于网络热词的频出,标准词库和停用词库也需要随之不断更新维护。
3.1.2 关键词指标
- 关键词重合度
- 新闻(内容)内频率,TF(Term Frequency)
- 衡量每个关键词在新闻(内容)里面是否高频
- 关键词在所有文档内出现的频率相反值,IDF(Inverse Document
Frequency)
- 如果一个关键词在某条新闻内出现的频率最大,在所有文档内出现频率小,则该关键词对这条新闻的特征标识作用越大
TF-IDF模型
每个关键词对新闻的作用衡量: TFIDF = TF * IDF
3.1.3 相关性算法
每一份新闻(内容)的特征,即可用关键词的集合来标识:
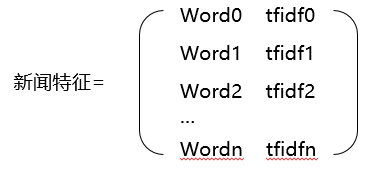
其中word0,1,2……n是新闻的所有关键词,tfidf0,1,2……n则是每个关键词的tfidf值
相关性计算:

3.1.4 用户特征
通过用户行为来获得,用户通过阅读、点赞、评论、分享来表达对新闻(内容)的喜爱;
对用户的各种行为赋予一定的“喜爱分”,例如阅读1分,点赞2分,评论5分等;
新闻(内容)特征 与用户行为分结合,即可得到用户的特征分。

随着用户阅读的新闻(内容)越来越多,该用户的标签也越来越多,并且越发精准;
当我们拿到新闻(内容)的特征后,就能与用户的关键词列表做匹配,得出用户阅读特征的匹配度,做出个性推荐。
3.1.5 其他运用
除了个性推荐,基于内容的相关性,可精准的给出一篇相关推荐列表;
3.1.6 优缺点
- 优点
对用户数量没有要求,与日活无关,个性化推荐的早期一般可采用此方式;
每个用户特征是由自己行为决定的,独立存在,不会相互干扰, 恶意刷阅读内容不会营销到推荐算法;
- 缺点
- 确定性太强,推荐内容均由用户历史访问决定,无法挖掘用户潜在兴趣
- 基于内容的推荐一般与其他推荐算法同时存在
3.2 基于用户的协同推荐
当具备内容协同过滤推荐后,推给用户的内容均为基于他们的阅读习惯来推荐,没能给用户“不期而遇”的感觉。
则,需要开始实现基于用户的协同过滤。
- 基于用户协同过滤推荐算法:
依据用户A的阅读喜好,为A找到与他兴趣最接近的群体; 即“人以群分”,把这个群体内其他人喜欢的,但A未阅读的推荐给A
3.2.1 用户群体划分
3.2.1.1 外部数据借用
使用第三方账户授权进入的,往往会包括性别、年龄、工作、甚至社交关系等
3.2.1.2 产品内主动询问
产品首次启动时的弹窗询问,“职业” “性别” 对内容的冷启动提供帮助, 但性价比偏低
3.2.1.3 对比用户特征
从内容的特征+用户的阅读数据 来得到用户特征,通过用户特征的相似性来划分群体
3.2.2 内容推荐实施
A B C D E 5个用户
阅读 1分,
赞 2分,
收藏 3分,
评论 4分,
分享 5分

各个用户的特征向量:

多维向量的距离需要通过欧几里得距离公式来计算,数值越小,向量距离约接近。

3.2.3 内容选取
假设用户X在系统归属于群体A,这个群体有n个用户,分别为A0,A1,A2……An,这些用户的集合用S(X,n)表示。
- 首先,我们需要把集合中所有用户交互过(阅读,评论等)的新闻提取出来;
- 需要剔除掉用户X已经看过的新闻,这些就不用再推荐了,剩下的新闻集合有m条,用N(X,m)来表示;
- 对余下的新闻进行评分和相似度加权的计算,计算包括两部分,一是用户X与S(X,n) 每一个用户的相似性,二是每个用户对新闻集N(X,m)中每条新闻的喜好,这样就能得到每条新闻相对于用户X的最终得分;
- 将N(X,m)中的新闻列表按照得分高低的顺序推荐给用户。
3.2.4 优缺点
- 优点
- 对分词算法的精确度无较强的要求
- 基于用户的行为数据去不断学习和完善
- 能发现用户潜在阅读兴趣,能“制造惊喜”
- 缺点
- 启动门槛高,用户量不够时几乎无法开展;
- 学习量不够时,推荐结果较差
About ME
👋 读书城南,🤔 在未来面前,我们都是孩子~
- 📙 一个热衷于探索学习新方向、新事物的智能产品经理,闲暇时间喜欢coding💻、画图🎨、音乐🎵、学习ing~
👋 Social Media
🛠️ Blog: http://oceaneyes.top
⚡ PM导航: https://pmhub.oceangzy.top
☘️ CNBLOG: https://www.cnblogs.com/oceaneyes-gzy/
🌱 AI PRJ自己部署的一些算法demo: http://ai.oceangzy.top/
📫 Email: 1450136519@qq.com
💬 WeChat: OCEANGZY
💬 公众号: UncleJoker-GZY
👋 加入小组~

👋 感谢打赏~

