自然语言处理基础知识
Natural Language Processing
自然语言发展历程
- 谷歌翻译,2016年上线全新版本神经网络翻译系统,基于RNN
- Facebook的FAIR(Facebook AI Research)发布《Convolutional Sequence to Sequence Learning》, 基于CNN的端到端训练
- 谷歌2017年6月发布《Attention is All you Need》,提出Transformer模型
- 自注意力 self-attention
- 多头注意力 multi-head attention
- 位置嵌入 positional encoding
- OpenAI 2018年发表《Improving Language Understanding by Generative
Pre-Training》,提出GPT模型,基于transformer提取特征,跑12个任务,9个任务都达到了最佳
- 单向语言模型
- AllenAI 2018年8月发表《Deep contextualized word
representations》,提出模型ELMo
- 双向LSTM语言模型
- 谷歌2018年10月,发表《Pre-training of Deep Bidirectional Transformers for Language Understanding》,提出BERT模型
- 百度的ERINE模型
- OpenAI 2019年2月提出GPT2.0,模型更深,训练数据更多,参数高达15亿
- 微软提出MASS模型,(Masked Sequence to Sequence Pre-training)
- 谷歌2019年6月提出XLNet
- Facebook2019年7月发表《RoBERTa: A Robustly Optimized BERT Pretraining Approach》,提出RoBERTa模型
- ……natural language processing
没有最强,只有更强。。。。
自然语言处理的任务应用
句法语义分析
对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧
信息抽取
从给定文本中抽取重要信息,比如抽取:
- 时间
- 地点
- 人物
- 事件
- 原因
- 结果
- 数字
- 日期
- 货币
- 专有名词
- ……
旨在了解谁在什么时候、什么原因、对谁 、做了什么事、有什么结果,涉及到实体识别、时间抽取、因果关系抽取等关键技术
文本挖掘
文本聚类、分类、信息抽取、摘要、情感分析以及对挖掘的信息和知识等可视化、交互式的表达界面
机器翻译
将输入的源语言文本通过自动翻译获得另外一种语言的文本。
根据输入媒介不同,细分为:
- 文本翻译
- 语音翻译
- 手语翻译
- 图形翻译
- ……
信息检索
对大规模的文档进行索引,可简单的对文档中的词汇赋予不同的权重来建立索引,可利用1,2,3的技术来建立更深层的索引
问答系统
对一个自然语言表达的问题,由问答系统给出一个精准的答案
需要对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别、形成逻辑表达式,然后在知识库中查找可能的候选答案并通过排序机制找出最佳答案
对话系统
系统通过一系列对话,跟用户进行聊天、回答、完成某一项任务
涉及到用户意图的理解、通过聊天引擎、问答引擎、对话管理技术,同时为体现和保证上下文的关联,需要具备多轮对话的能力
自然语言处理模型
Seq2Seq模型
- encoder层
- decoder层
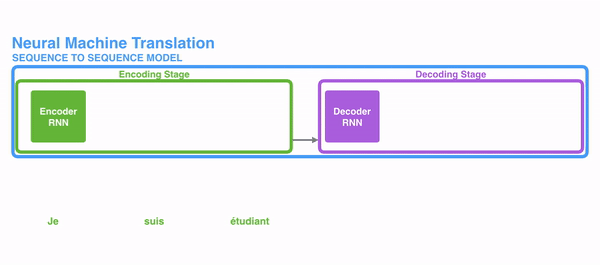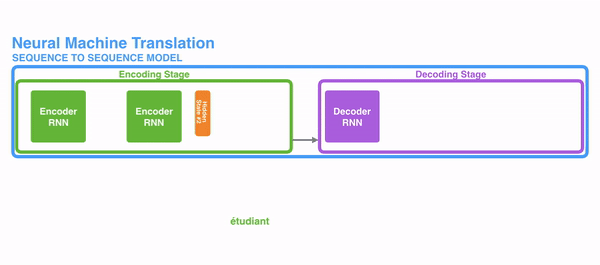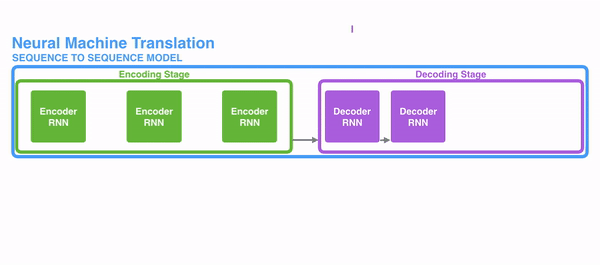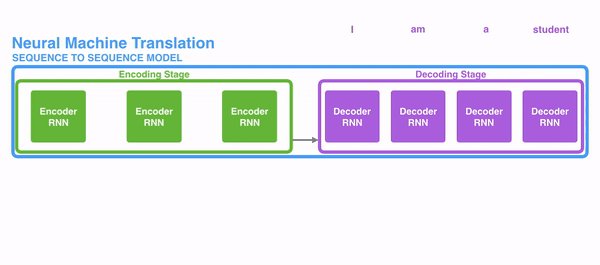
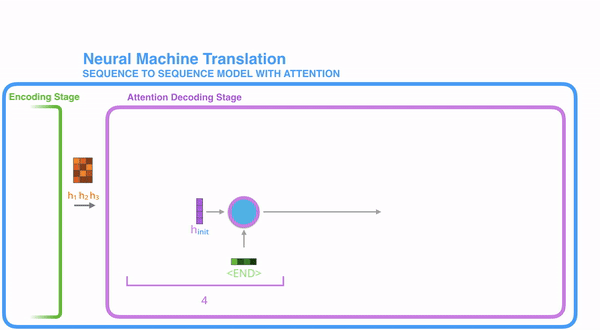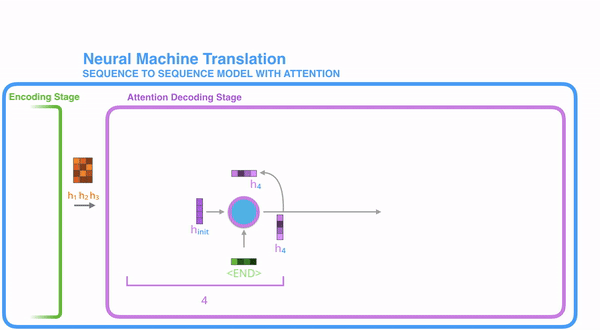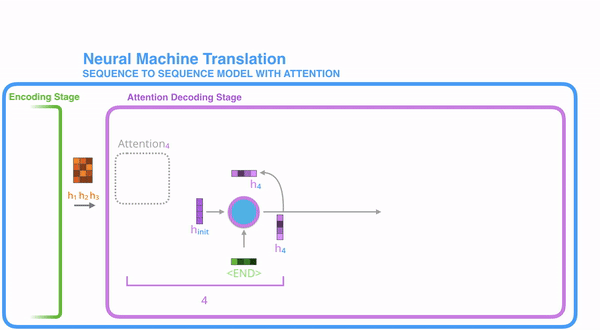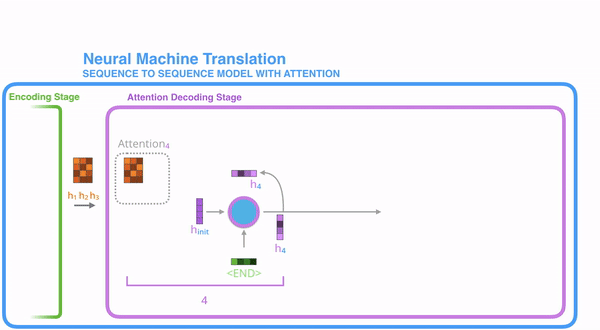
1、在encode阶段,第一个节点输入一个词,之后的节点输入的是下一个词语前一个节点的 hidden state,最终encoder会输出一个context
2、这个context又作为decoder的输入,每经过一个decoder的节点就输出一个翻译后的词,并将decoder的 hidden state作为下一层的输入
该模型对短文本的翻译而言效果较好,但存在一定的缺点,如果文本稍长,就容易丢失文本的一些信息
Attention
Attention是一种能让模型对重要信息进行重点关注并充分学习吸收的技术
Attention注意力,该模型在decoder阶段,会选择最适合当前节点的context作为输入
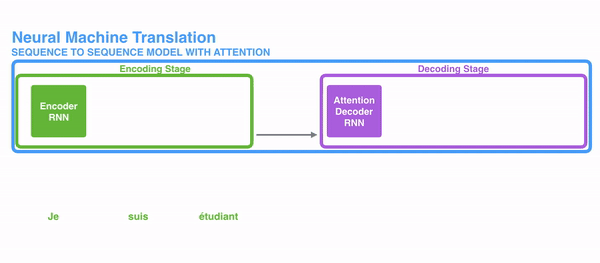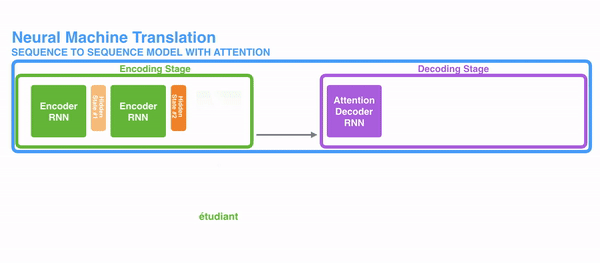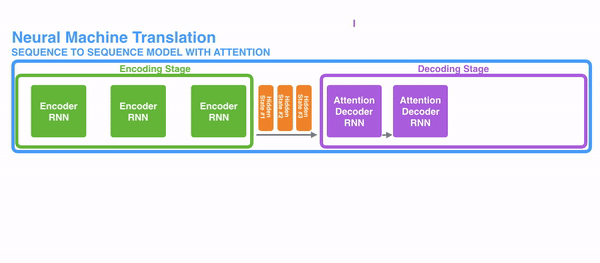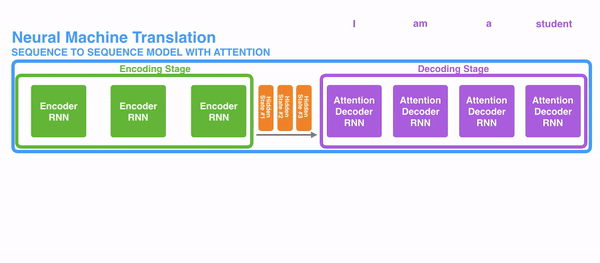
1、encoder提供更多的数据给到decoder,encoder会把所有节点的hidden state提供给decoder,而不仅仅是encoder的最后一个节点的hidden state
2、decoder并不是直接吧所有的encoder提供的hidden state作为输入,而是采取一种选择机制,把最符合当前位置的hidden state选出来
- 确定哪个hidden state与当前节点关系最为密切
- 计算每一个hidden state的分值
- 对每个分数值做一个softmax的计算,使得相关性高的hidden state的分数值更大,相关性低的hidden state分数值更低

1)把每一个encoder节点的hidden states的值 与decoder当前节点的上一个节点的hidden state相乘, 得到每个encoder节点的每个hidden state的分数
2)将得到的分数进行softmax计算,计算之后的值即为每一个encoder节点的 hidden states 对于当前节点的权重
3)将权重与原hidden states相乘并相加,得到的结果即为当前节点的hidden state
decoder层的工作原理
第一个decoder的节点初始化一个向量,并计算当前节点的hidden state
将得到的hidden state作为第一个节点的输入,经过RNN节点后得到一个新的hidden state与输出值
区别:
seq2seq是直接把输出值作为当前节点的输出
Attention是把该值与hidden state做成一个链接,并把连接好的值作为context,送入一个前馈神经网络,最终当前节点的输出内容由该网络决定
把连接好的值作为context,送入一个前馈神经网络,最终当前节点的输出内容由该网络决定
重复以上步骤,直到把所有的 coder的节点都输出相应的内容
Attention模型并不只是盲目地将输出的第一个单词与输入的第一个词对齐,实际在训练阶段学习了如何在语言中对齐单词。
Attention函数的本质,可被描述为一个查询(query)到一系列(键key -值value)对的映射
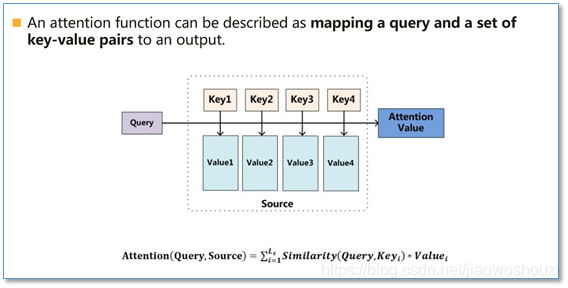
计算attention的主要步骤
- 首先将query 和每个key进行相似度计算得到权重,常用的相似度函数又点积,拼接,感知机等
- 然后使用一个softmax函数对这些权重进行归一化
- 最后将权重和相应的键值value进行加权求和,得到最后的attention
目前在NLP研究中,key和value常常都是一个,key = value
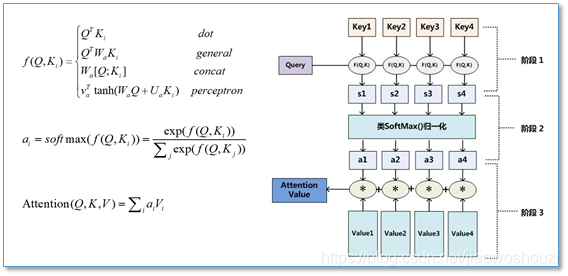
Transformer模型
《Attention is all you need》
1、不同于以往的主流机器翻译使用基于RNN的seq2seq模型框架,使用attention机制代替了RNN
2、提出多头注意力(Multi-headed attention)机制方法,在编码器和解码器内大量使用多头自注意力机制(Multi-headed self-attent)
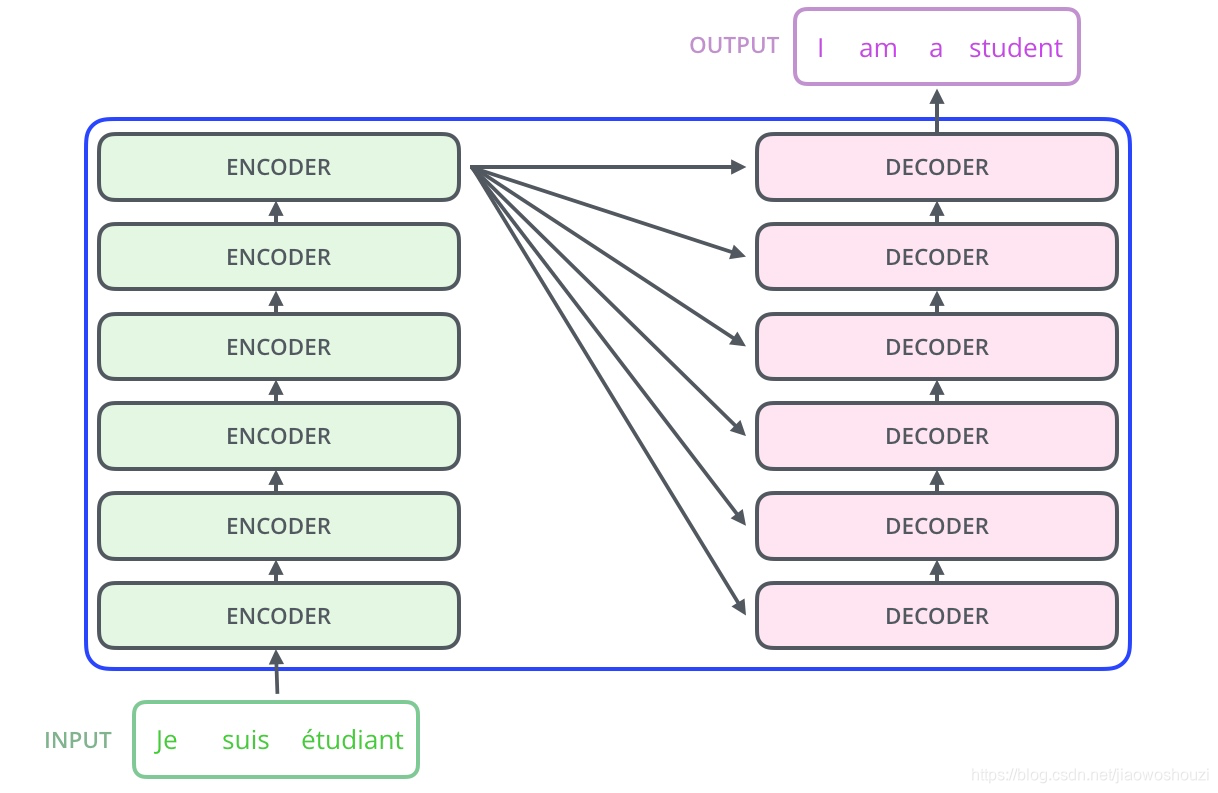
Transformer总结结构
和Attention模型一样,Transformer也采用了encoder-的 coder架构,但其结构更加复杂,encoder层u由6个encoder组成, decoder层也由6个decoder组成
每个encoder和decoder的简版结构
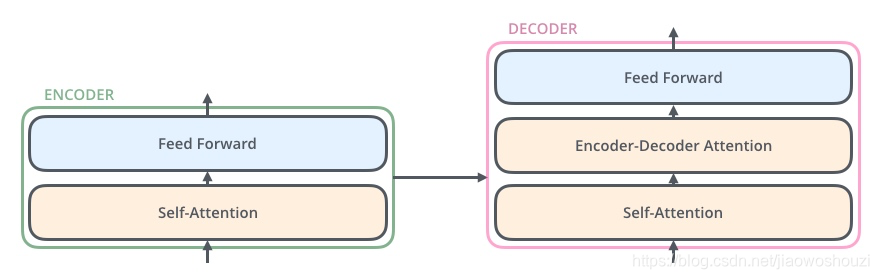
- encoder
- self-attention,帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义
- 前馈神经网络
模型内部细节
1、首先对输入的数据进行 embedding,降维,可以理解为类似word 2 vector 的操作
2、embedding结束之后,输入到encoder层
3、self-attention处理完数据之后把数据送给前馈神经网络
4、前馈神经网络可并行进行计算
5、将计算的输出 输入到下一个encoder
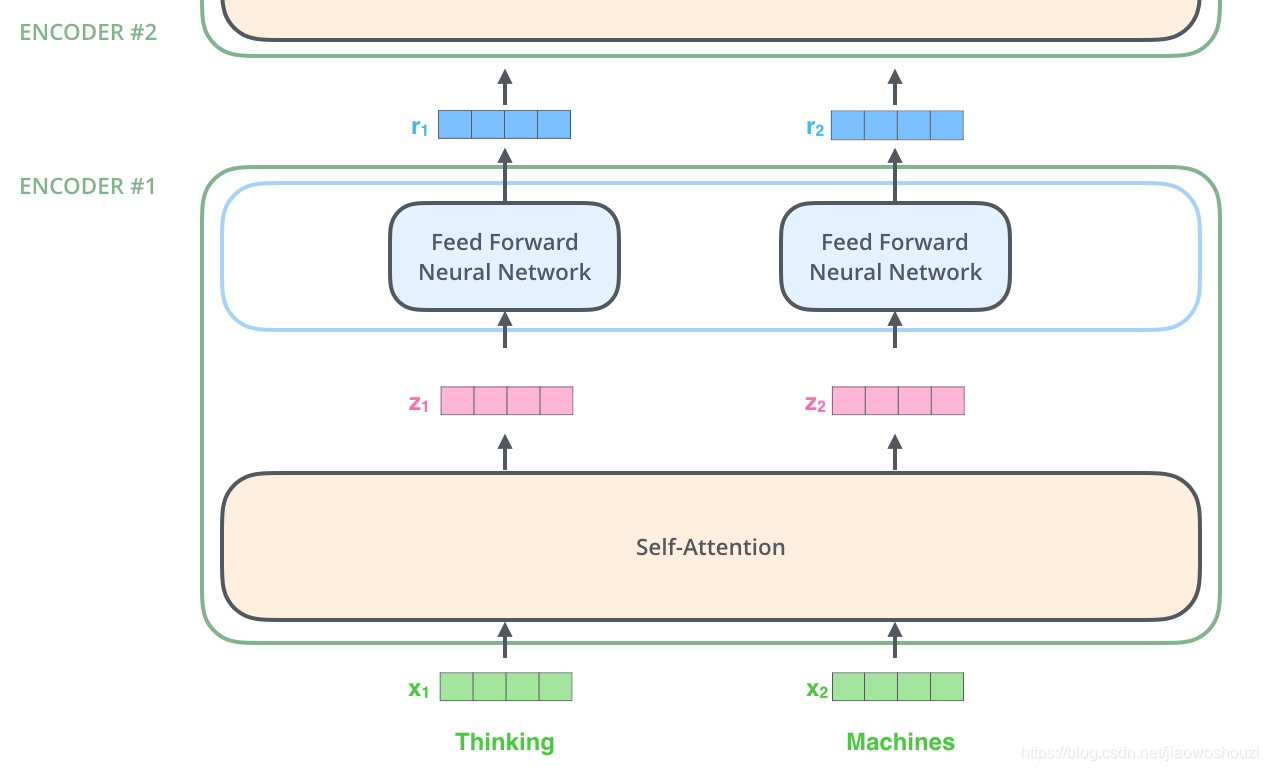
- decoder
- self-attention,帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义
- Encoder-Decoder Attention,帮助当前节点获取当前需要关注的重点内容
- 前馈神经网络
self-attention
About ME
👋 读书城南,🤔 在未来面前,我们都是孩子~
- 📙 一个热衷于探索学习新方向、新事物的智能产品经理,闲暇时间喜欢coding💻、画图🎨、音乐🎵、学习ing~
👋 Social Media
🛠️ Blog: http://oceaneyes.top
⚡ PM导航: https://pmhub.oceangzy.top
☘️ CNBLOG: https://www.cnblogs.com/oceaneyes-gzy/
🌱 AI PRJ自己部署的一些算法demo: http://ai.oceangzy.top/
📫 Email: 1450136519@qq.com
💬 WeChat: OCEANGZY
💬 公众号: UncleJoker-GZY
👋 加入小组~

👋 感谢打赏~

