自然语言的几个重要模型-学习记录
自然语言的几个重要模型-学习记录
- 循环神经网络 (序列模型序列依赖问题)
- 双向循环神经网络(输入序列正向和反向依赖问题)
- 深度双向循环神经网络
- LSTM(梯度消失问题)
- GRU
- text CNN(一维卷积和池化)
- seq2seq(序列到序列问题)
- Attention(decoder对encoder输入序列注意力问题,从输入获取可用信息)
- Transform(对输入的序列分成q检索项 k键项 v值项进行计算,矩阵并行计算)
- 语言预训练方法ELMO (使用双向rnn组合中间层权重)
- 语言预训练方法BERT ERNIE (使用transform encoder部分无需标签,ERNIE主要处理中文场景按词mask)
- 语言预训练方法GPT (使用transform decoder部分)
1.循环神经网络
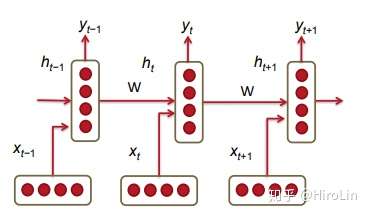
- 使用隐藏层保留之前时间步的信息
- 梯度裁剪 处理梯度爆炸问题,即超出阈值怎重置为阈值。因为在RNN中目标函数有关隐藏状态的梯度会因为时间步数较大或时间步较小而变大。
2.双向循环神经网络
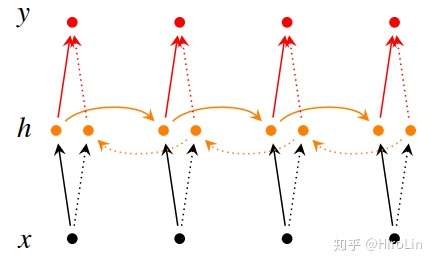
(橘色的实线和虚线分别是前向传递和后向传递的过程 )
- 通常RNN输入序列是按顺序输入,但此时就会丢失从后往前的数据。双向RNN就是前后各有一个网络,对各自输出的向量进行整合。
3.深度双向循环神经网络
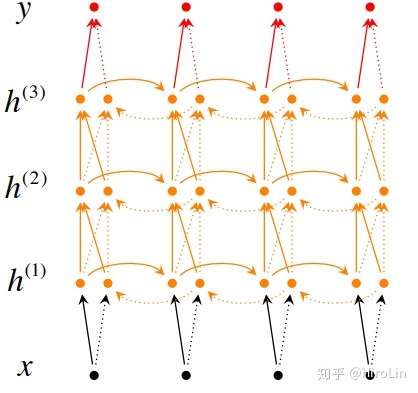
- 叠加多层双向RNN
4.LSTM
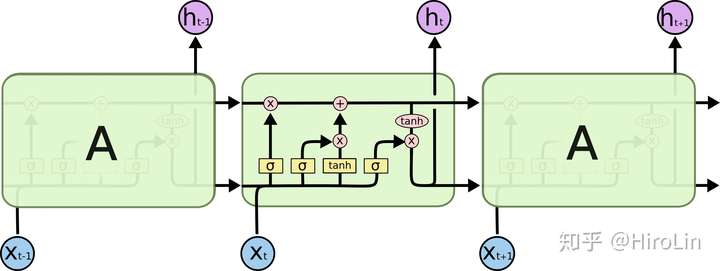
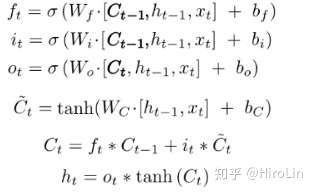
- 包含了三个门,输入门 输出门 遗忘门
- 缓解了梯度消失的问题
5.GRU
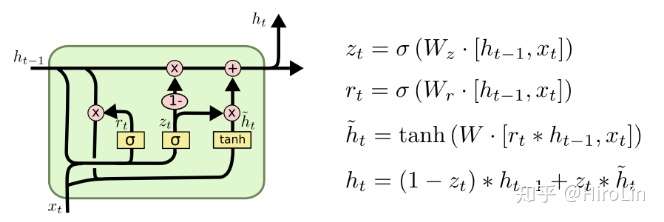
- 包含重置门和更新门
- 缓解了梯度消失的问题
6.textCNN
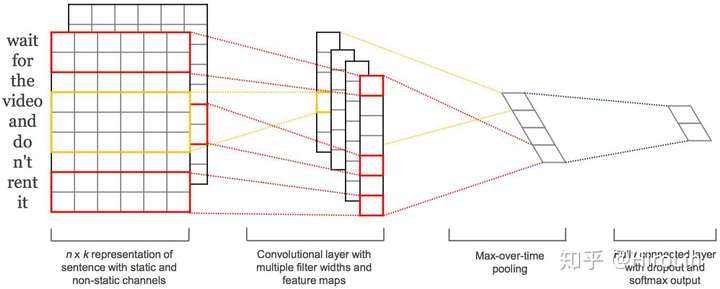
如上图输入每个单词用5维词向量表示,即输入的通道是5. 输入宽度是7. 红色框卷积核宽是4 所以得到的输出向量长度是7-4+1=4,再对通道做池化得到最后的向量进行拼接 再使用全连接层进行业务逻辑处理例如分类
- 使用一维卷积来捕获位置相近词的关联
- 时序最大池化层
7.seq2seq
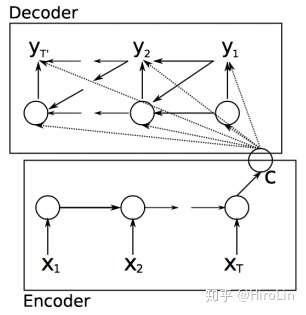
- 序列到序列模型 使用Encoder编码器生成序列到向量。Decoder解码器从向量生成文本
- encoder的输出是c=f(h1, h2...),在计算y输出时使用了相同的背景变量c。(但例如在翻译场景输出是关联到输入的某个词的,所以引入了带注意力机制的seq2seq)
- 输出y是一个概率模型(例如输出y1可能有 “越” 50%可能性、“跃”10%可能性、......)选择哪一个值有三种方式。
- 贪婪搜索 只取概率最大的 ,但是这种情况并非能取到全局最优解。因为前几个词选择直接影响到后面几个词。
- 穷举搜索 量太大了。。
- 束搜索 束宽k 每次取前k个 最后在候选取分最高得。
8.Attention注意力机制
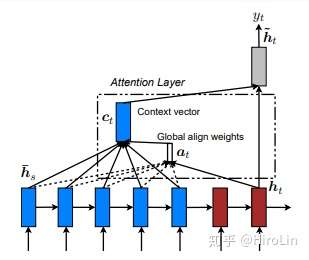
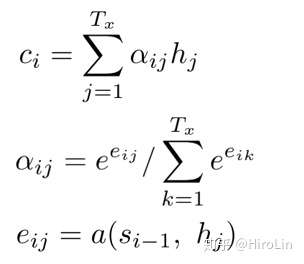
- 如上图可以看出decoder的输出受到上一时刻输出、上一时刻隐含层变量和当前时间步背景向量影响。背景向量即所有编码器隐含层的加权平均得到。ci即为背景向量。
- ci最终是由解码器在i-1时刻的隐藏状态和编码器在j时刻的隐藏状态得到,具体怎么组合原文中提供了三种方法(第一种类似直接求内积..):

- 得到了输入所需要得上一时刻输出、上一时刻隐含层变量和当前时间步背景向量后,接下来就是如何组合这三个输入得到输出。使用门控循环单元进行组合。
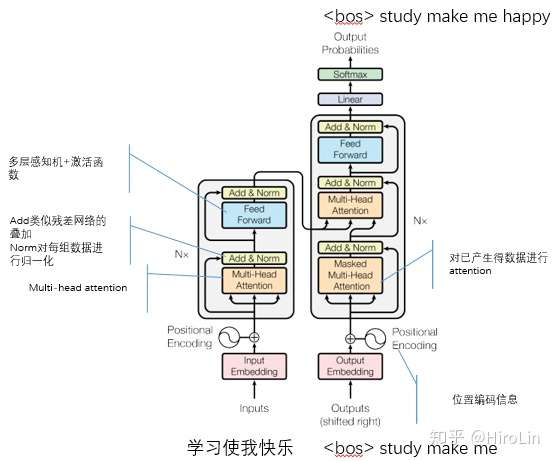
9.Transform
变换器模型不同于RNN的架构(下一步计算都依赖前一步的输出,无法并行)。使用矩阵运算得到计算效率更高的模型。
最终的公式:
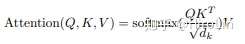
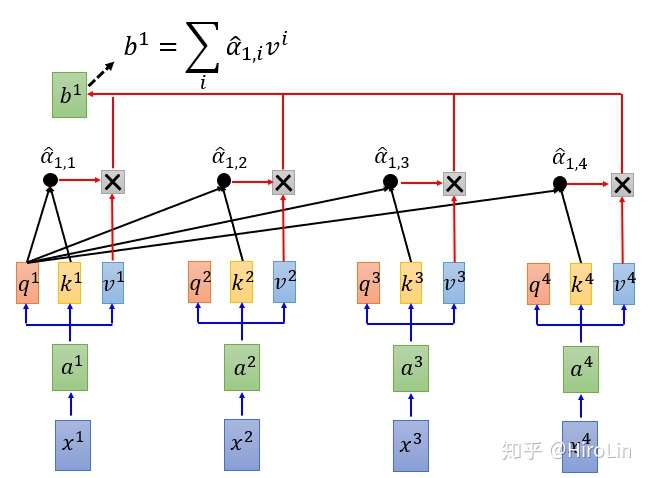
- 由上图得到对于输入x分别通过三个不同的矩阵得到q(检索项)k(键值项)v(值项)。q1项分别与其他几个键值项点乘再得到所有q1计算得到的值求softmax,再和v值项相乘求和。同样得得到q2、q3、q4得出结果。该计算得过程是并行的。
- 多头注意力机制即每个x输入将会输出多组q k v如下图,计算规则基本一致。
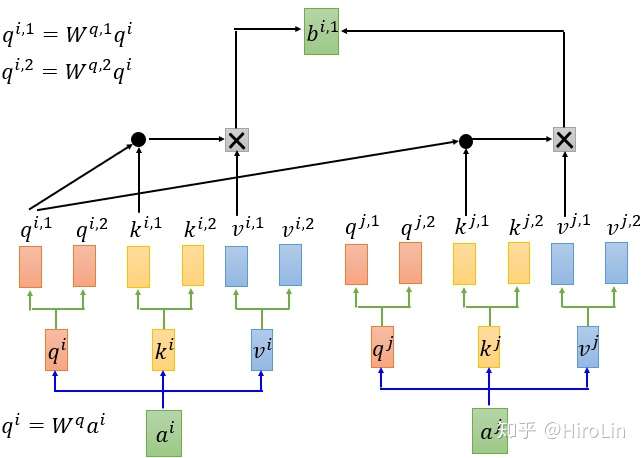
- 通过上述描述可以看出在计算过程中没有词的位置信息。所以在进行x->a的变换过程中,将a增加位置信息编码。
- 完整Transform
10.语言模型预训练方法ELMO
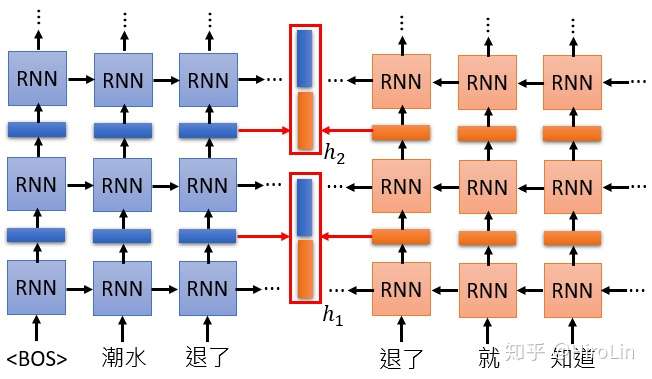
- elmo使用双向rnn对文本进行训练得到中间层向量抽取后进行组合。组合的参数也是学出来了。原论文中r'n'n部分使用lstm实现
11.语言模型预训练方法BERT
- Bert使用transform的encoder部分,所以可以进行无标签学习
- bert训练方法一 有15%的字会被MASK隐藏,这样学出来的被遮挡的词就会有相似的词向量。
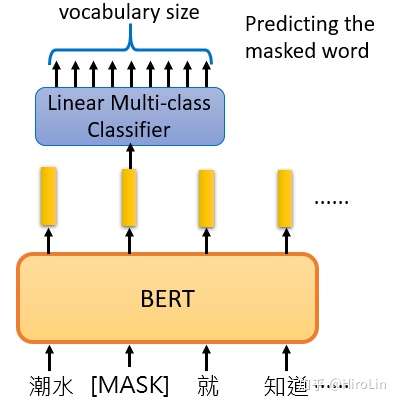
- bert训练方法二 句子是否是相邻的判断。用SEP进行链接
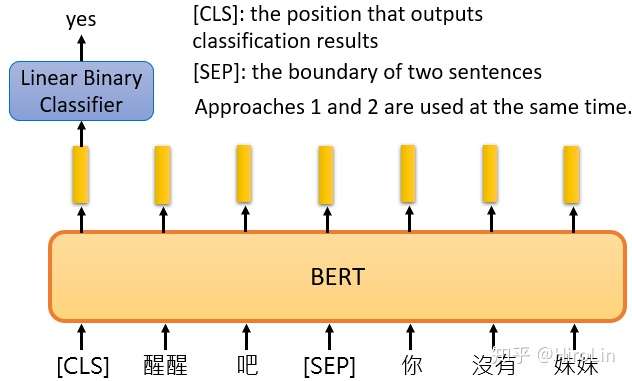
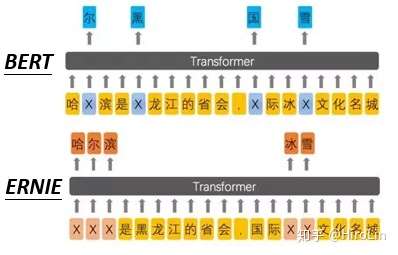
- ERNIE 由上述可以看出Bert是对字进行MASK,对于中文场景进行的词MASK更合理,如下图。目前百度paddlepaddle已经发布开源版本。
12.语言模型预训练方法GPT
- 使用transform的decoder部分。
- 目前最大模型是1.5G 但是没有release最终版本
13.词向量计算相关模型word2vec和glove fasttext
About ME
👋 读书城南,🤔 在未来面前,我们都是孩子~
- 📙 一个热衷于探索学习新方向、新事物的智能产品经理,闲暇时间喜欢coding💻、画图🎨、音乐🎵、学习ing~
👋 Social Media
🛠️ Blog: http://oceaneyes.top
⚡ PM导航: https://pmhub.oceangzy.top
☘️ CNBLOG: https://www.cnblogs.com/oceaneyes-gzy/
🌱 AI PRJ自己部署的一些算法demo: http://ai.oceangzy.top/
📫 Email: 1450136519@qq.com
💬 WeChat: OCEANGZY
💬 公众号: UncleJoker-GZY
👋 加入小组~

👋 感谢打赏~


本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 OCAEN.GZY读书城南!